Introduction
Intermittent demand occurs when products or services have irregular purchase patterns with frequent zero-value periods. This is common in retail, spare parts inventory, and specialty products where demand is irregular rather than continuous. Forecasting these patterns accurately is essential for optimizing stock levels, reducing costs, and preventing stockouts. TimeGPT excels at intermittent demand forecasting by capturing complex patterns that traditional statistical methods miss. This tutorial demonstrates TimeGPT’s capabilities using the M5 dataset of food sales, including exogenous variables like pricing and promotional events that influence purchasing behavior.What You’ll Learn
- How to prepare and analyze intermittent demand data
- How to leverage exogenous variables for better predictions
- How to use log transforms to ensure realistic forecasts
- How TimeGPT compares to specialized intermittent demand models
How to Use TimeGPT to Forecast Intermittent Demand
Step 1: Environment Setup
Start by importing the required packages for this tutorial and create an instance ofNixtlaClient.
Step 2: Load and Visualize the Dataset
Load the dataset from the M5 dataset and convert theds column to a datetime object:
| unique_id | ds | y | sell_price | event_type_Cultural | event_type_National | event_type_Religious | event_type_Sporting |
|---|---|---|---|---|---|---|---|
| FOODS_1_001 | 2011-01-29 | 3 | 2.0 | 0 | 0 | 0 | 0 |
| FOODS_1_001 | 2011-01-30 | 0 | 2.0 | 0 | 0 | 0 | 0 |
| FOODS_1_001 | 2011-01-31 | 0 | 2.0 | 0 | 0 | 0 | 0 |
| FOODS_1_001 | 2011-02-01 | 1 | 2.0 | 0 | 0 | 0 | 0 |
| FOODS_1_001 | 2011-02-02 | 4 | 2.0 | 0 | 0 | 0 | 0 |
plot method:
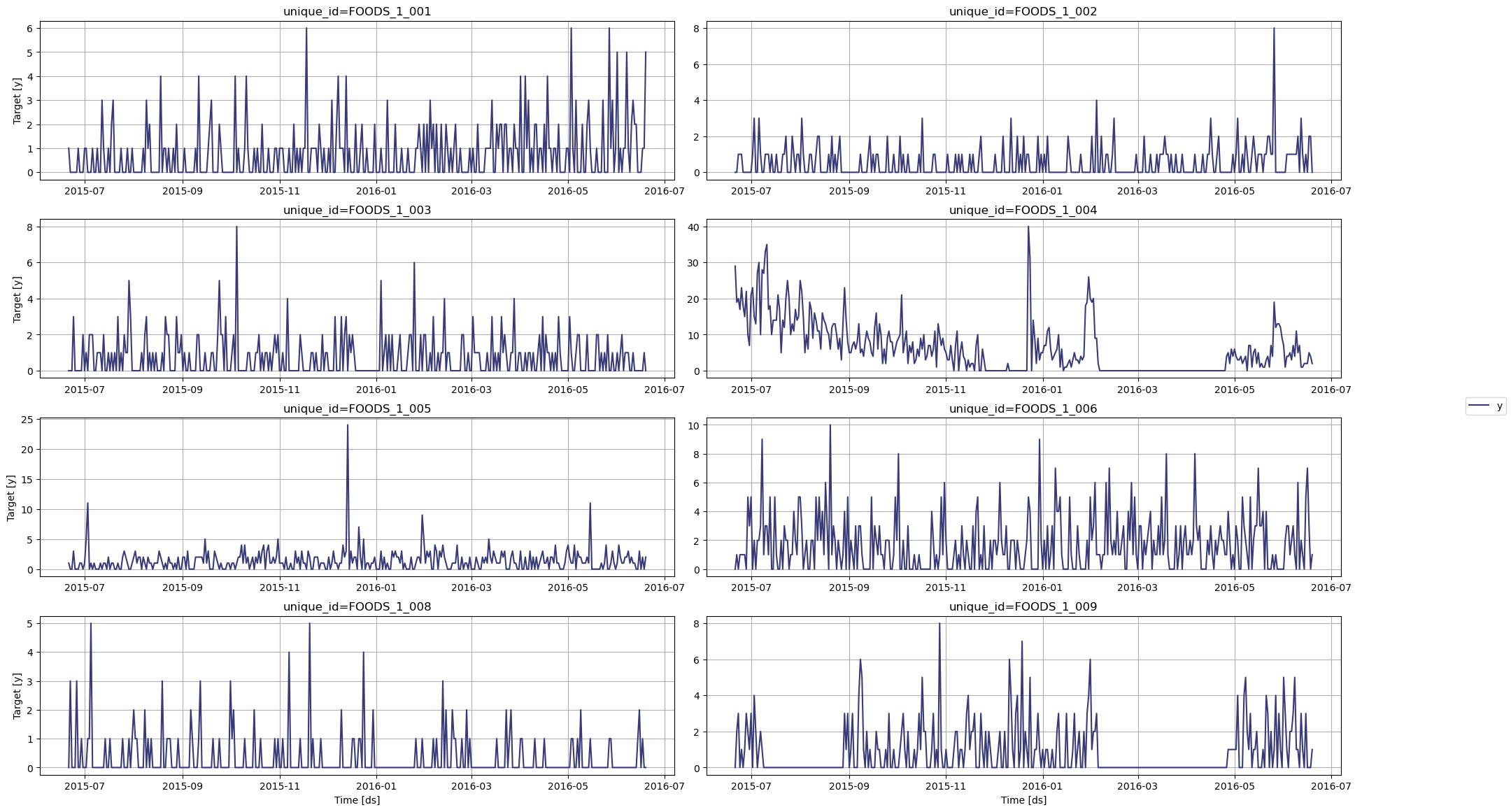
Step 3: Transform the Data
To avoid getting negative predictions coming from the model, we use a log transformation on the data. That way, the model will be forced to predict only positive values. Note that due to the presence of zeros in our dataset, we add one to all points before taking the log.Step 4: Forecast with TimeGPT
Forecast with TimeGPT using theforecast method:
| unique_id | ds | TimeGPT | TimeGPT-lo-80 | TimeGPT-hi-80 | |
|---|---|---|---|---|---|
| 0 | FOODS_1_001 | 2016-05-23 | 0.286841 | -0.267101 | 1.259465 |
| 1 | FOODS_1_001 | 2016-05-24 | 0.320482 | -0.241236 | 1.298046 |
| 2 | FOODS_1_001 | 2016-05-25 | 0.287392 | -0.362250 | 1.598791 |
| 3 | FOODS_1_001 | 2016-05-26 | 0.295326 | -0.145489 | 0.963542 |
| 4 | FOODS_1_001 | 2016-05-27 | 0.315868 | -0.166516 | 1.077437 |
Step 5: Evaluate the Forecasts
Before measuring the performance metric, let’s plot the predictions against the actual values.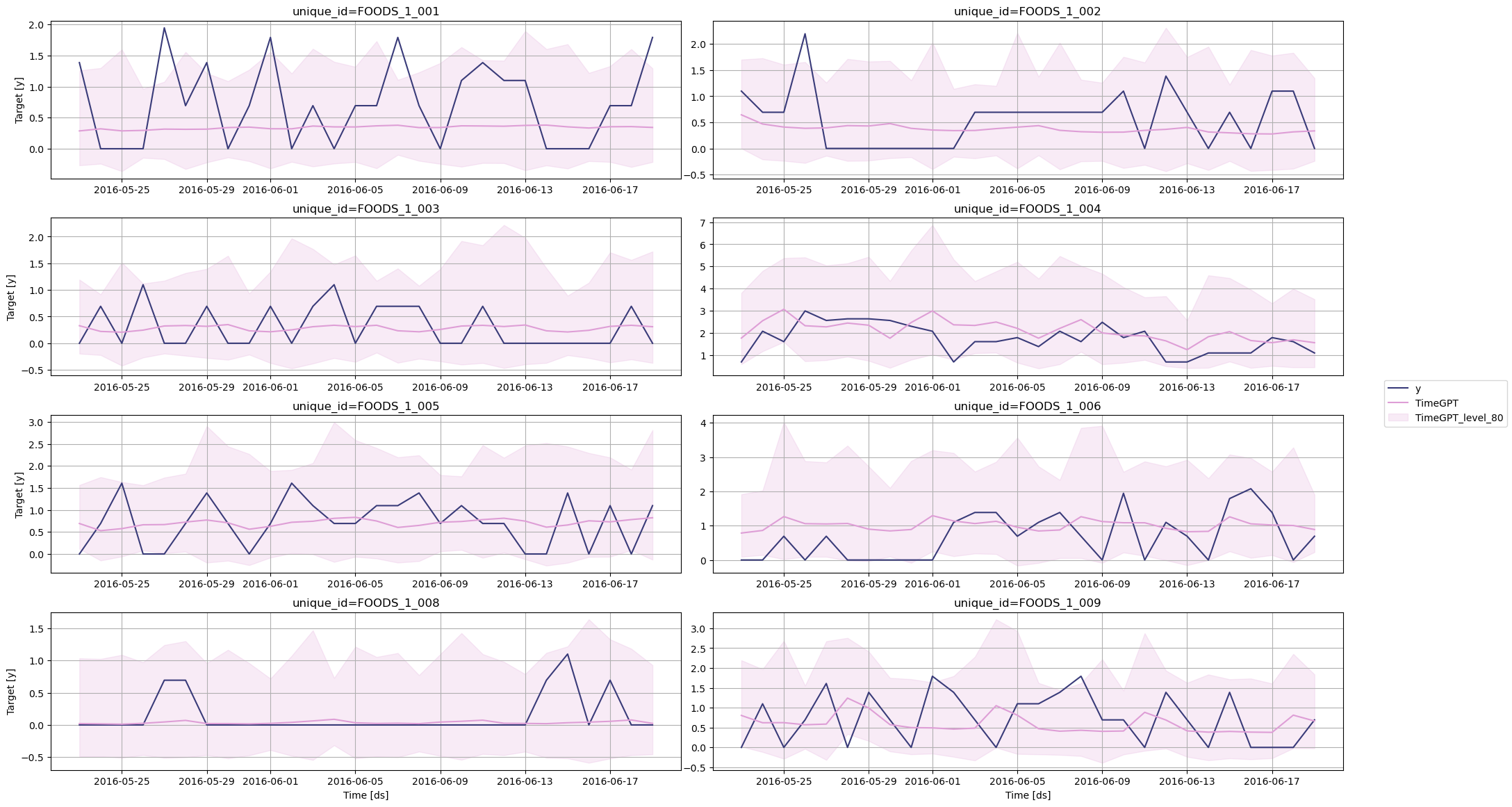
Step 6: Compare with Statistical Models
The librarystatsforecast by Nixtla provides a suite of statistical models specifically built for intermittent forecasting, such as Croston, IMAPA and TSB. Let’s use these models and see how they perform against TimeGPT.
| unique_id | ds | CrostonClassic | CrostonOptimized | IMAPA | TSB | |
|---|---|---|---|---|---|---|
| 0 | FOODS_1_001 | 2016-05-23 | 0.599093 | 0.599093 | 0.445779 | 0.396258 |
| 1 | FOODS_1_001 | 2016-05-24 | 0.599093 | 0.599093 | 0.445779 | 0.396258 |
| 2 | FOODS_1_001 | 2016-05-25 | 0.599093 | 0.599093 | 0.445779 | 0.396258 |
| 3 | FOODS_1_001 | 2016-05-26 | 0.599093 | 0.599093 | 0.445779 | 0.396258 |
| 4 | FOODS_1_001 | 2016-05-27 | 0.599093 | 0.599093 | 0.445779 | 0.396258 |
| unique_id | ds | y | sell_price | event_type_Cultural | event_type_National | event_type_Religious | event_type_Sporting | TimeGPT | TimeGPT-lo-80 | TimeGPT-hi-80 | CrostonClassic | CrostonOptimized | IMAPA | TSB | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | FOODS_1_001 | 2016-05-23 | 1.386294 | 2.24 | 0 | 0 | 0 | 0 | 0.286841 | -0.267101 | 1.259465 | 0.599093 | 0.599093 | 0.445779 | 0.396258 |
| 1 | FOODS_1_001 | 2016-05-24 | 0.000000 | 2.24 | 0 | 0 | 0 | 0 | 0.320482 | -0.241236 | 1.298046 | 0.599093 | 0.599093 | 0.445779 | 0.396258 |
| 2 | FOODS_1_001 | 2016-05-25 | 0.000000 | 2.24 | 0 | 0 | 0 | 0 | 0.287392 | -0.362250 | 1.598791 | 0.599093 | 0.599093 | 0.445779 | 0.396258 |
| 3 | FOODS_1_001 | 2016-05-26 | 0.000000 | 2.24 | 0 | 0 | 0 | 0 | 0.295326 | -0.145489 | 0.963542 | 0.599093 | 0.599093 | 0.445779 | 0.396258 |
| 4 | FOODS_1_001 | 2016-05-27 | 1.945910 | 2.24 | 0 | 0 | 0 | 0 | 0.315868 | -0.166516 | 1.077437 | 0.599093 | 0.599093 | 0.445779 | 0.396258 |
| metric | TimeGPT | CrostonClassic | CrostonOptimized | IMAPA | TSB |
|---|---|---|---|---|---|
| mae | 0.492559 | 0.564563 | 0.580922 | 0.571943 | 0.567178 |
Step 7: Use Exogenous Variables
To forecast with exogenous variables, we need to specify their future values over the forecast horizon. Therefore, let’s simply take the types of events, as those dates are known in advance. You can also explore using date features and holidays as exogenous variables.| unique_id | ds | event_type_Cultural | event_type_National | event_type_Religious | event_type_Sporting | |
|---|---|---|---|---|---|---|
| 0 | FOODS_1_001 | 2016-05-23 | 0 | 0 | 0 | 0 |
| 1 | FOODS_1_001 | 2016-05-24 | 0 | 0 | 0 | 0 |
| 2 | FOODS_1_001 | 2016-05-25 | 0 | 0 | 0 | 0 |
| 3 | FOODS_1_001 | 2016-05-26 | 0 | 0 | 0 | 0 |
| 4 | FOODS_1_001 | 2016-05-27 | 0 | 0 | 0 | 0 |
forecast method and pass the futr_exog_df in the X_df parameter.
| unique_id | ds | TimeGPT_ex | TimeGPT-lo-80 | TimeGPT-hi-80 | |
|---|---|---|---|---|---|
| 0 | FOODS_1_001 | 2016-05-23 | 0.281922 | -0.269902 | 1.250828 |
| 1 | FOODS_1_001 | 2016-05-24 | 0.313774 | -0.245091 | 1.286372 |
| 2 | FOODS_1_001 | 2016-05-25 | 0.285639 | -0.363119 | 1.595252 |
| 3 | FOODS_1_001 | 2016-05-26 | 0.295037 | -0.145679 | 0.963104 |
| 4 | FOODS_1_001 | 2016-05-27 | 0.315484 | -0.166760 | 1.076830 |
| unique_id | ds | y | sell_price | event_type_Cultural | event_type_National | event_type_Religious | event_type_Sporting | TimeGPT | TimeGPT-lo-80 | TimeGPT-hi-80 | CrostonClassic | CrostonOptimized | IMAPA | TSB | TimeGPT_ex | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | FOODS_1_001 | 2016-05-23 | 1.386294 | 2.24 | 0 | 0 | 0 | 0 | 0.286841 | -0.267101 | 1.259465 | 0.599093 | 0.599093 | 0.445779 | 0.396258 | 0.281922 |
| 1 | FOODS_1_001 | 2016-05-24 | 0.000000 | 2.24 | 0 | 0 | 0 | 0 | 0.320482 | -0.241236 | 1.298046 | 0.599093 | 0.599093 | 0.445779 | 0.396258 | 0.313774 |
| 2 | FOODS_1_001 | 2016-05-25 | 0.000000 | 2.24 | 0 | 0 | 0 | 0 | 0.287392 | -0.362250 | 1.598791 | 0.599093 | 0.599093 | 0.445779 | 0.396258 | 0.285639 |
| 3 | FOODS_1_001 | 2016-05-26 | 0.000000 | 2.24 | 0 | 0 | 0 | 0 | 0.295326 | -0.145489 | 0.963542 | 0.599093 | 0.599093 | 0.445779 | 0.396258 | 0.295037 |
| 4 | FOODS_1_001 | 2016-05-27 | 1.945910 | 2.24 | 0 | 0 | 0 | 0 | 0.315868 | -0.166516 | 1.077437 | 0.599093 | 0.599093 | 0.445779 | 0.396258 | 0.315484 |
| metric | TimeGPT | CrostonClassic | CrostonOptimized | IMAPA | TSB | TimeGPT_ex |
|---|---|---|---|---|---|---|
| mae | 0.492559 | 0.564563 | 0.580922 | 0.571943 | 0.567178 | 0.485352 |
Conclusion
TimeGPT provides a robust solution for forecasting intermittent demand:- ~14% MAE improvement over specialized models
- Supports exogenous features for enhanced accuracy
Next Steps
- Explore other use cases with TimeGPT
- Learn about probabilistic forecasting with prediction intervals
- Scale your forecasts with distributed computing
- Fine-tune models with custom loss functions